
Investors poured over $9.5 billion into AI processor startups in 2024, betting on architectures that could reshape inference economics. NVIDIA itself projects the broader AI-infrastructure market could reach $3,4 trillion by 2030. That kind of capital rarely gathers around incremental improvements, it usually signals an architectural inflection point. Yet GPUs still dominate both training and most inference workloads today, so any transition will be evolutionary before it is disruptive.
We may nonetheless be entering one of those rare moments when the entire compute stack is re-examined. The GPUs that won the training race are beginning to show limits for certain inference workloads, particularly those involving long-form reasoning and token-by-token generation. These models can demand orders of magnitude more sequential compute per request than simple chatbots, not a thousandfold across the board, but enough to expose where GPUs’ parallel strengths taper off.
The Architecture Problem
GPUs were optimized for training: massive parallel operations across millions of parameters. Training is largely parallelizable, a batch can be split across thousands of cores and synchronized periodically, though at scale even training is bounded by communication overheads. Inference, by contrast, especially autoregressive inference, introduces a stronger sequential component. Each new token depends on the previous ones, which reduces opportunities for parallel execution at small batch sizes.
Even with advances such as speculative decoding, multi-token prediction, and faster memory hierarchies, the sequential nature of reasoning models creates persistent pressure on memory bandwidth. The real constraint increasingly lies in moving data between memory and compute, not just raw arithmetic throughput.
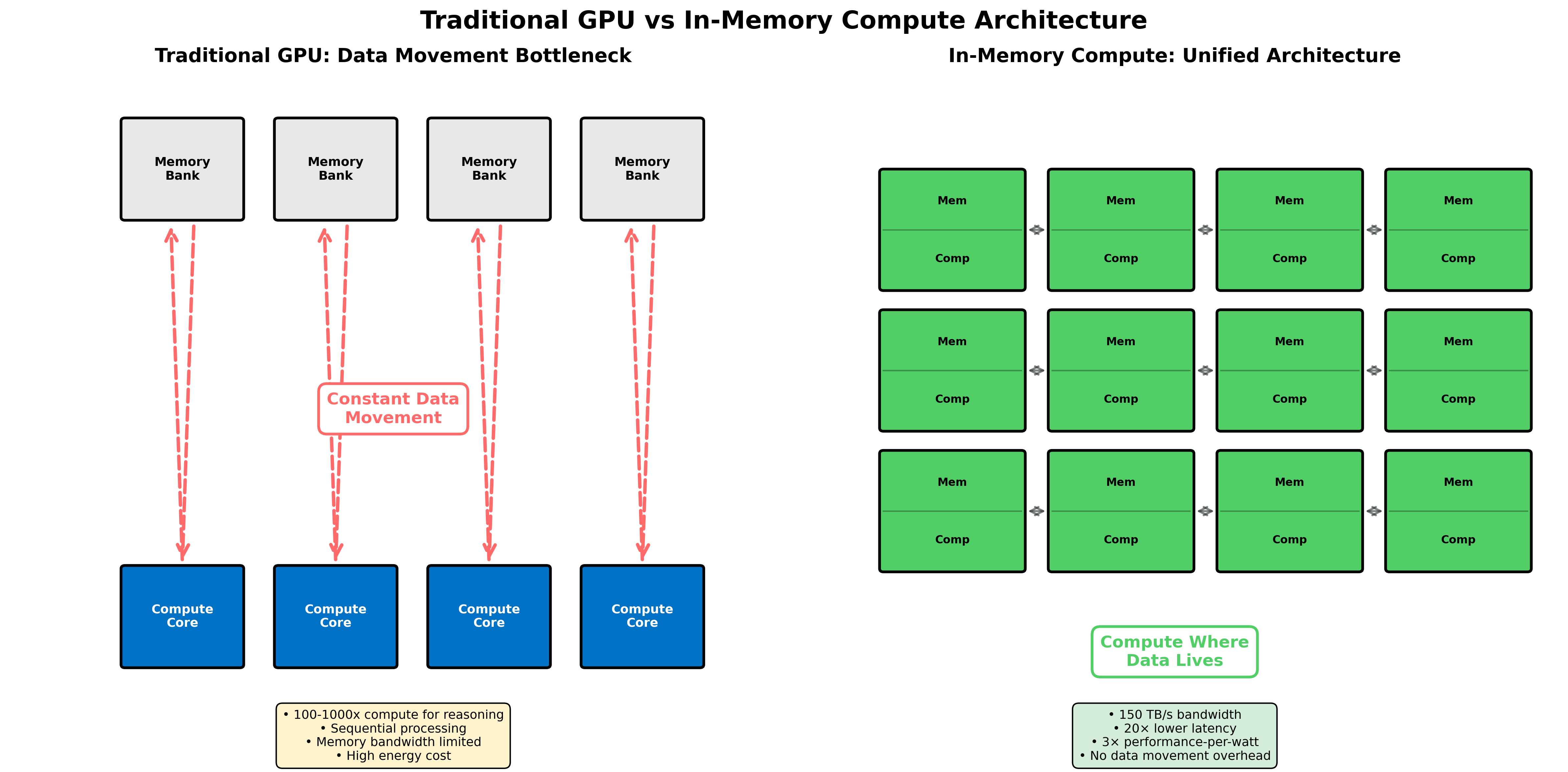
New Architectural Directions
A wave of startups is tackling this imbalance from different angles.
In-memory compute aims to minimize data movement by performing operations where data already resides. Companies like d-Matrix report on-chip bandwidths above 100 TB/s, roughly an order of magnitude higher than typical GPU memory links, by keeping activations in local memory rather than shuttling them across buses.
Wafer-scale integration takes another approach: make the chip so large that inter-chip communication nearly disappears. Cerebras built a single wafer-scale device whose internal fabric provides several-thousand-fold higher on-wafer bandwidth compared with conventional off-package links, allowing entire models to reside on one piece of silicon.
Deterministic architectures, like Groq’s LPU, embrace predictable, ordered execution, especially valuable for batch-1, low-latency inference. In those scenarios, Groq reports multi-fold speedups in token generation relative to GPU baselines.
Advanced packaging and memory designs blend chiplets, stacked HBM, and custom interconnects to improve energy efficiency. Rebellions cites multi-× performance-per-watt gains from such techniques.
Each of these represents directional innovation rather than settled fact, but collectively they capture an industry searching for architectures tuned to inference constraints.
Early Deployments
Some of these technologies are already escaping the lab. Meta has tested Cerebras and Groq hardware for early Llama-series deployments. Aramco and SK Telecom have announced pilot programs exploring wafer-scale and deterministic accelerators. Groq Cloud reports more than two million registered developers. Cerebras, which disclosed triple-digit-million revenue in 2024, expects rapid growth as pilots expand.
The technical elegance is real; the adoption curve is only beginning.
The CUDA Problem
Here the excitement meets hard reality: none of this matters if developers can’t, or won’t, move their workloads.
NVIDIA’s moat isn’t just silicon; it’s CUDA, a decade of compiler optimization, libraries, tooling, and institutional knowledge. Every ML engineer learned to code against it. Every major framework treats CUDA as the default backend. Switching costs are as much organizational as technical.
Startups argue that inference changes the calculus. Once models are trained and architectures stabilize, efficiency gains matter more than framework familiarity. At hyperscaler scale, even partial ports become worthwhile when they cut infrastructure costs by double digits. Evidence is emerging that this is true at the frontier: hyperscalers are already deploying heterogeneous silicon,TPUs, Trainium, Maia, and custom ASICs, where economics justify the effort.
But for the vast majority, mid-market firms, AI-feature startups, enterprise adopters,CUDA’s ecosystem advantage remains overwhelming: mature tools, rich debugging, abundant talent. Moving off that foundation means rebuilding more than code.
Infrastructure Transitions and Path Dependence
This tension between technical inevitability and installed-base inertia echoes every infrastructure transition. Railroads superseded canals only after decades; AC outlasted DC because of economics, not initial ubiquity; packet-switched networks displaced circuit-switched telephony only when costs and flexibility became undeniable.
The same dynamic will shape AI compute. Better technology wins when economic advantage overwhelms switching costs. Sometimes incumbents absorb the innovation; other times we end up with bifurcated markets, where the frontier moves ahead and the mainstream stays put.
This time the cycle is compressed into years, not decades. Capital is abundant, and national interests are now intertwined with semiconductor strategy, Rapidus’s $12 billion government-backed 2 nm foundry in Japan being one example. AI infrastructure has become strategic infrastructure.
The Software Layer Question
Which brings the story full circle. Hardware elegance alone rarely wins. The real contest may hinge on the software abstraction layer.
If one of these startups,or a hyperscaler,can make its architecture as accessible as CUDA, the balance could shift quickly. High-level compilers that target multiple backends efficiently; compatibility layers that let existing models run without rewrite; optimization tools that automatically map workloads to the right hardware, these could dissolve the moat.
Hyperscalers already build such layers internally, abstracting hardware choice behind unified frameworks. If those abstractions become open or standardised, developers could become architecture-agnostic, letting efficiency and cost decide.
But building that layer is daunting. It means compilers, profilers, debuggers, integration with PyTorch and TensorFlow, all the unglamorous tooling NVIDIA spent a decade perfecting. Replicating that while scaling hardware manufacturing is the hardest part of the race.
What’s Next
We are witnessing something significant. The innovations are real, memory-centric compute, wafer-scale silicon, deterministic execution, advanced packaging, and so is the market validation. The capital commitment is undeniable.
So too is NVIDIA’s software moat and the massive installed base that anchors it.
The likely outcome may not be abrupt displacement but stratification: GPUs continue to dominate general-purpose and batched inference, while specialized accelerators capture latency-sensitive or energy-bound niches.
As history shows,from RISC vs CISC to x86 vs ARM,architectural transitions usually end in coexistence rather than replacement. The $9.5 billion bet is that economics and physics will eventually force change; experience suggests the future will be more nuanced than that.
We’re still watching an extraordinary moment unfold in computing infrastructure, one defined not by replacement, but by diversification and re-balancing across the stack.